Introduction
Your learning platform includes the Content recommendation system, an AI-powered recommendation engine whose responsibility is to produce different kinds of personalized suggestions. To learn more about where and how suggestions come into play in your learning platform, refer to the Content recommendation chapter of the article FAQs on Docebo artificial intelligence features.
To enable or disable content recommendation, access the Navigation menu > Configuration (spanner icon) > Platform setup and tools > Artificial intelligence, then press the Enable/Disable button in the Content recommendation card.
This article provides an overview of the general principles and the techniques that are used by content recommendation to compute and deliver these suggestions, as well as of the information about learners and training materials that it currently leverages.
History-based suggestions
Our personalized suggestions derive from the analysis of learners’ history within the learning platform. That means that the principal source of information for content recommendation is the cumulative sequence of interactions that each learner has had with the various learning materials in the learning platform.
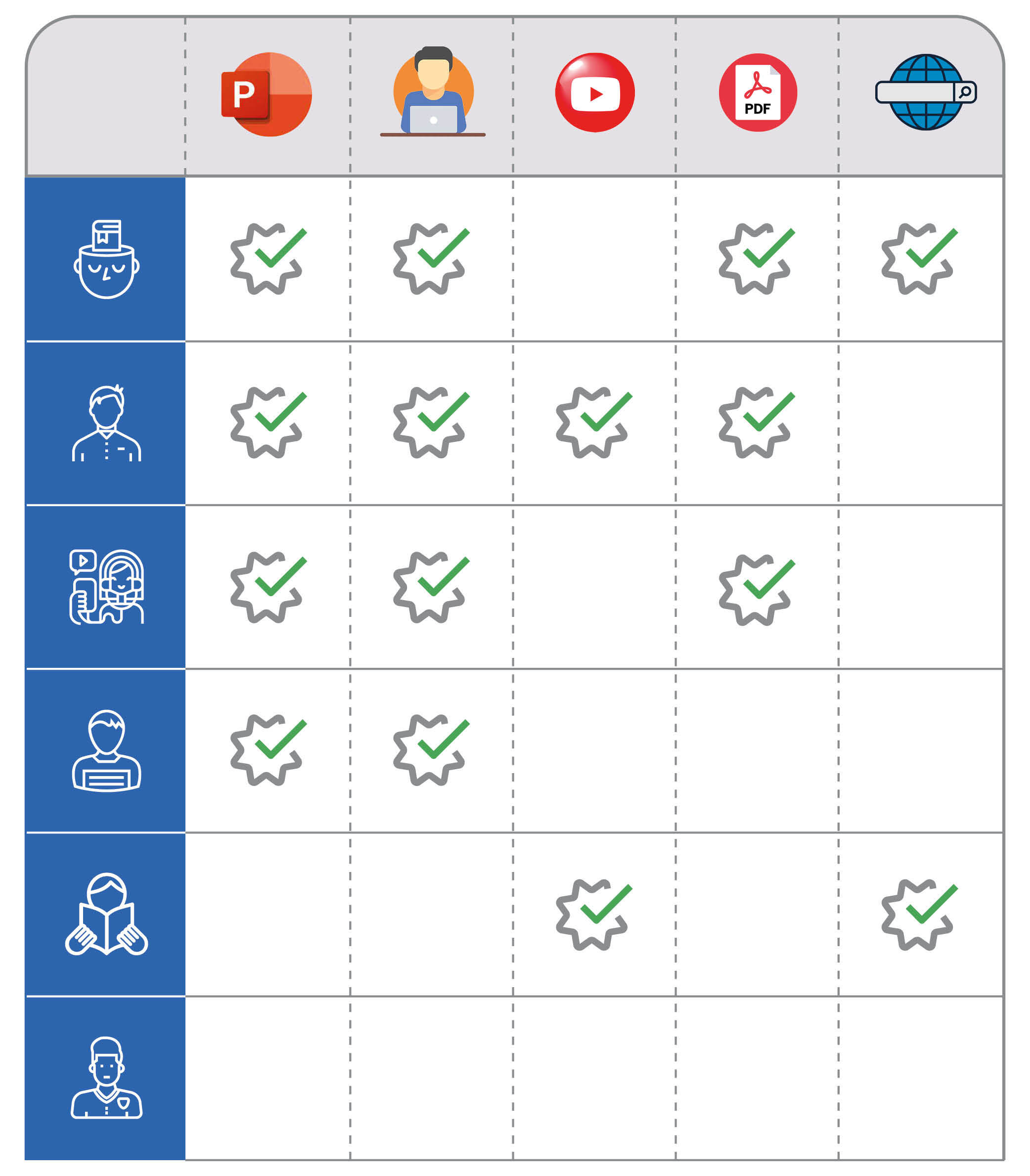
More specifically, content recommendation considers the following interactions:
- The completion of courses
- The views and the rating of an asset and the invitations made to other learners to view that asset
Content recommendation uses this interaction history to build a large matrix of users vs. content. An intuitive view of this matrix is shown below.
From this matrix, content recommendation is able to derive, using a well-known matrix factorization algorithm, a multi-dimensional metric space, in which users and pieces of content are embedded within the same system of coordinates. A representation of such a metric space is visible below.
Please note: for display purposes, a two-dimensional metric space is presented here, whereas in a real case the metric space will have a much larger number of dimensions.
The benefit of such a metric space is that we can derive measures of distance or proximity between users and pieces of content; in other words, we can tell which users are close to which pieces of content.
The proximity interpretation is of particular interest: for instance, when a user U is particularly close to a content C in their metric space, it means that content C has been viewed by other users that have a history of interactions particularly similar to that of U.
This is the basis for producing our personalized suggestions: content recommendation computes the distances between users and embedded content in the metric space according to the matrix factorization algorithm and extracts those pieces of content that are closest to a particular user, since they are the ones which are most likely of interest to that user.
Further considerations also apply: obviously no pieces of content that the user has already viewed are suggested; moreover, only those pieces of content made accessible to a specific user will be suggested, in order to respect the visibility rules of the teaching materials that have been set in your learning platform.
Contextualized suggestions
Content recommendation also leverages the proximity in between different pieces of content, to add contextualization to the suggestions produced for a given user U. It considers the last content C viewed by U (or the one currently being viewed), and computes what other pieces of content are the closest to C in the metric space. These will be part of the suggestions, together with the pieces of content closest to U.
Working with short history
Since content recommendation is currently based on interaction history that accumulates over time as users take advantage of training materials in the platform when a brand new platform is launched there is no sufficient data to produce significant suggestions. As more interactions occur within the platform, however, content recommendation is able to populate the matrix, and as a general rule, the more the learning platform is used, the more specific and personalized the suggestions will become.
Likewise, when a user's history is empty or very short - such as a new user on the platform, or some users who rarely interact with any content - content recommendation may not produce suggestions for that user. But as the user grasps more and more opportunities to learn within her platform, he or she will start to see personalized tips appearing.
Updating the interaction history
As learners continue to use the learning platform and interact with pieces of content, the matrix capturing their interaction history of course changes. Content recommendation re-computes that matrix periodically to reflect the latest interactions, then re-applies the matrix factorization algorithm to create an up-to-date metric space.
Since in a real use case the interaction matrix can become very large and the computations required to obtain the matrix and the corresponding metric space take a long time, we currently schedule such an update procedure for any given learning platform every few days. For this reason, it's important to remember that the latest interactions between users and content may not be taken into account when computing their personalized suggestions, until the next update iteration for your learning platform takes effect.
Technical limitations
The content recommendation feature has limitations when handling large datasets. The likelihood of encountering these limitations increases as the total number of users and content items grows, especially when many users interact with multiple items. In such cases, the platform provides non-AI suggestions to ensure users continue receiving relevant recommendations.
Though there is no strict limit, the content recommendation system may approach its threshold once the product of the number of users and content items nears one billion—particularly in high-engagement contexts. Even in these large-scale situations, fallback methods maintain a consistent flow of suggestions.